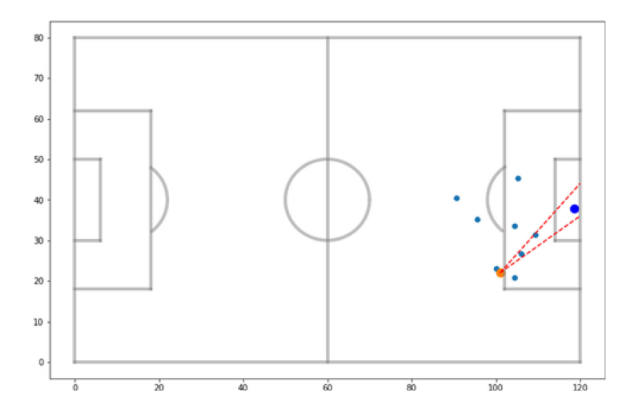
Bayesian model averaging for logistic regression: Evaluating shooting skills of soccer players
Nov 22, 2024
Data
Hewitt and Karakuş (2023)
A primer on non-collapsibility
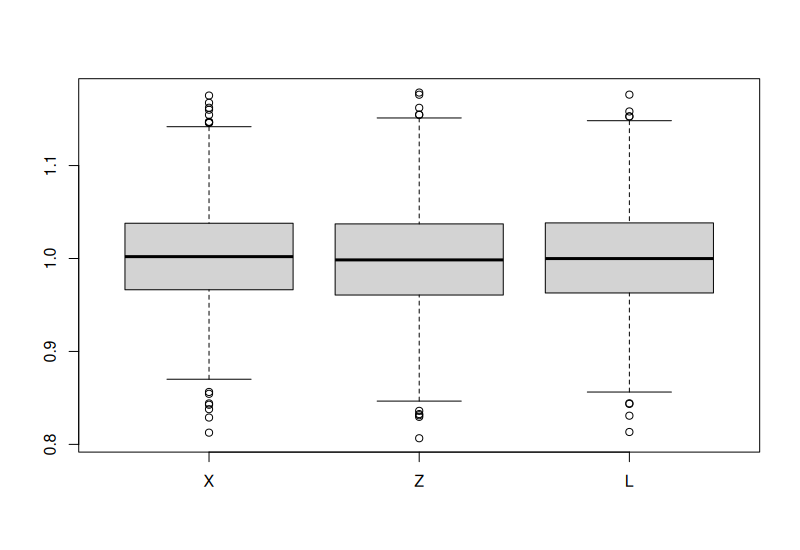
Estimate for \(\beta_1\) in 1000 simulations (\(m_3\) is correct model):
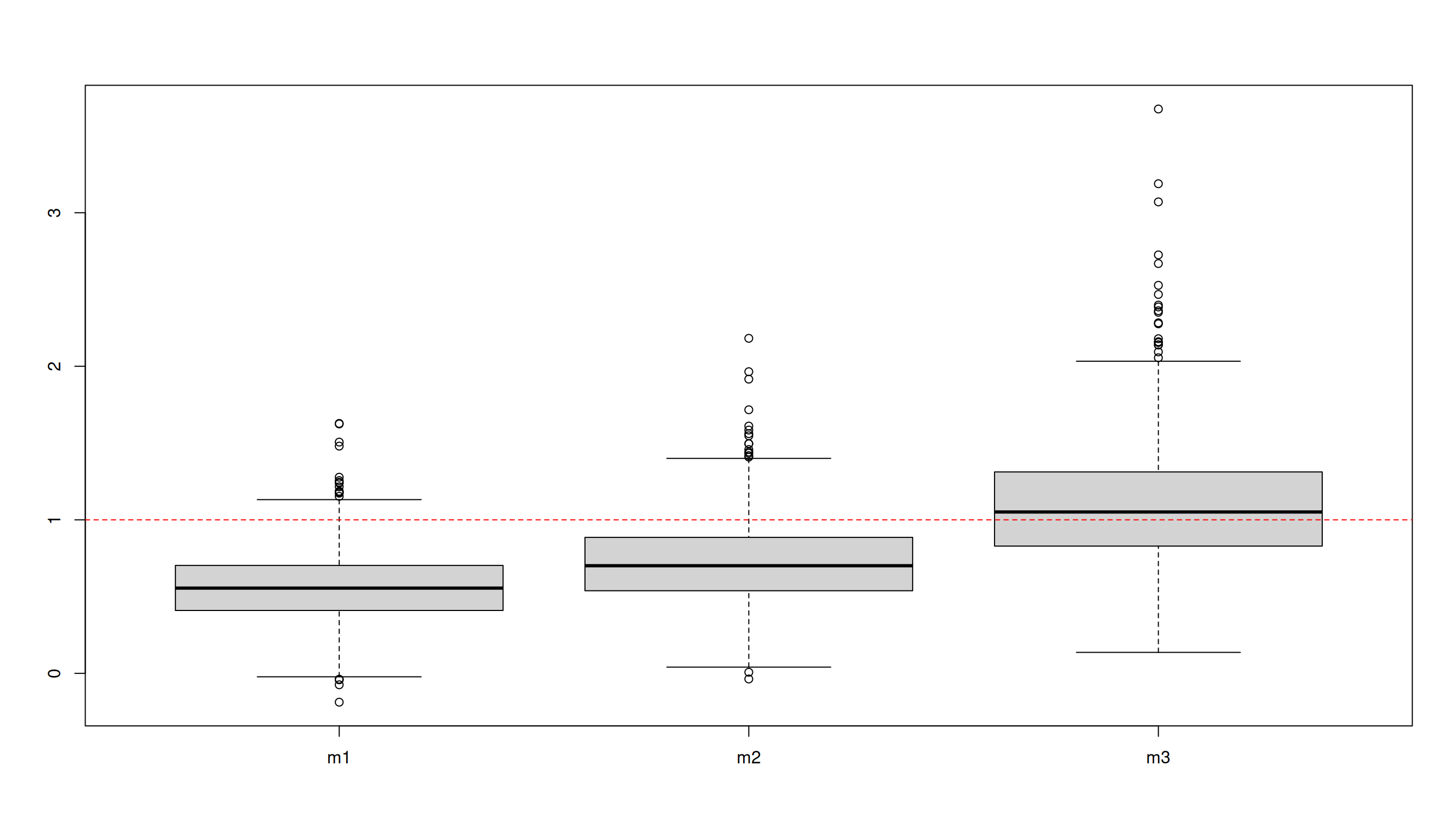
Linear model comparison
As comparison: \(Y = X + Z + L - L_1 + \epsilon, \quad \epsilon \sim \text{N(0,1)}.\)
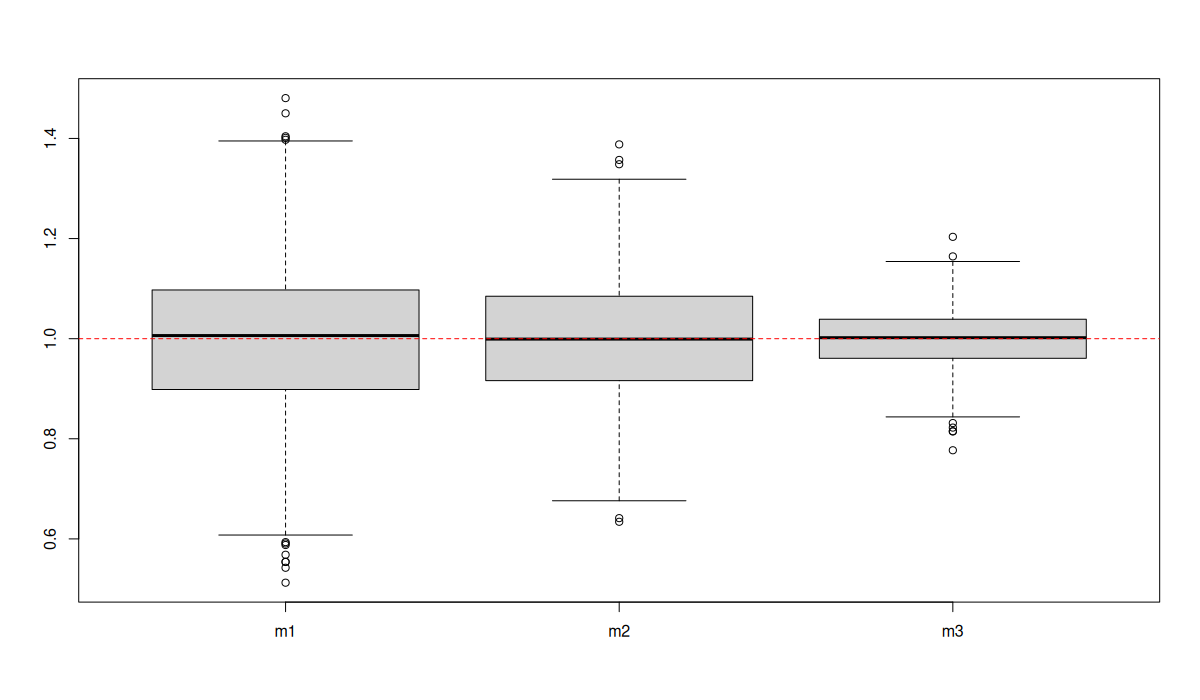
Non-collapsibility in BMA??
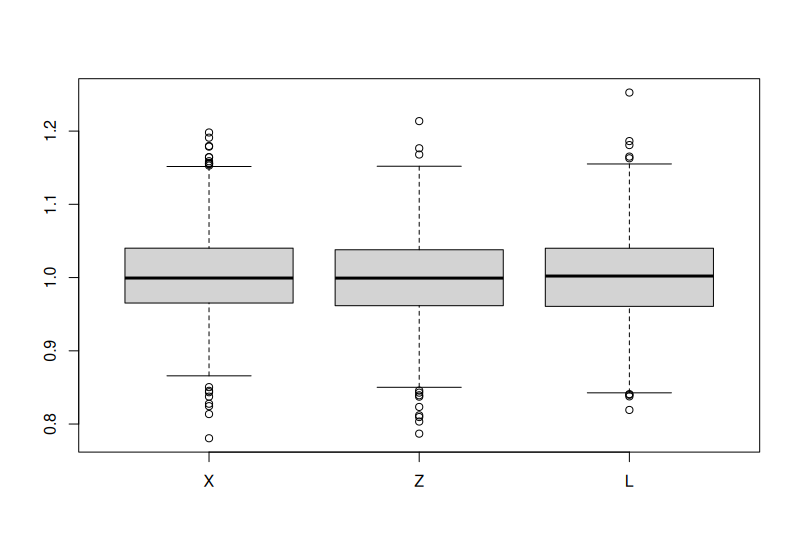
Posterior means from 1000 simulations:
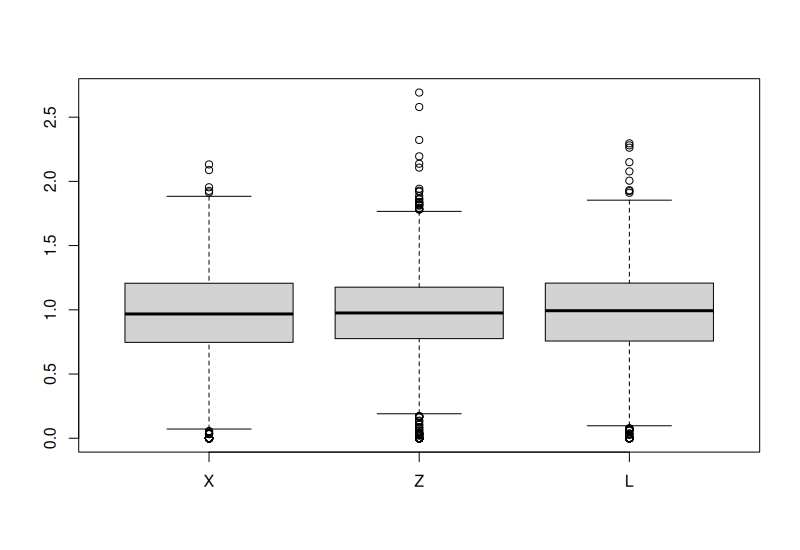
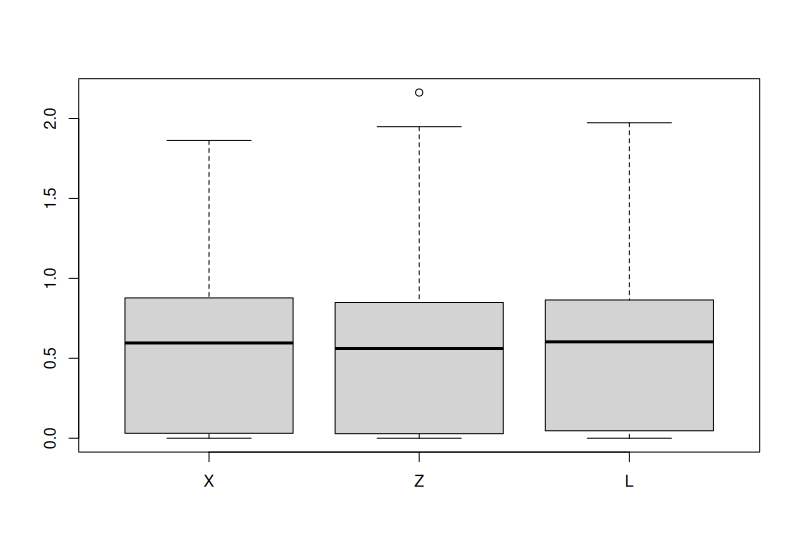
Linear Model BMA
As comparison: \(Y = X + Z + L - L_1 + \epsilon, \quad \epsilon \sim \text{N(0,1)}.\)